Home > Courses
Data Science
Course Description

Assignments & Case Studies

Real-Time Data Science Project

Job Readiness Program

Lifetiime access to study material
Skill Covered

Statistics

Artificial intelligence
Deep Learning

Data Mining

Data Analysis

Big Data Technologies
Prediction algorithms

Data Governance
Data Science involves extracting insights and knowledge from large and complex datasets. It combines various disciplines, including statistics, machine learning, data analysis, and domain expertise, to solve real-world problems. Data scientists collect, clean, and analyze data to uncover trends, patterns, and valuable information that can inform decision-making and drive innovation. They utilize programming languages like Python and R, alongside tools like Jupyter notebooks and libraries like pandas and scikit-learn, to process data and build predictive models. Data Science has applications in numerous fields, including healthcare, finance, marketing, and technology, where it enables organizations to make data-driven decisions and gain a competitive edge.
In addition, Data Science involves a cyclical process, often referred to as the Data Science pipeline. This process typically includes stages such as data collection, data preprocessing, exploratory data analysis (EDA), feature engineering, model building, model evaluation, and deployment. Throughout these stages, data scientists work to ensure data quality, handle missing values, and select appropriate algorithms to build predictive models. The ultimate goal is to extract actionable insights, create data-driven solutions, and drive business value. As the demand for data-driven decision-making continues to grow, Data Science remains a critical field, offering exciting career opportunities and the potential to revolutionize industries.
Course detail
Data Science Course Curriculum
Python
- Introduction to Python and IDEs – The basics of the Python programming language, how you can use various IDEs for python development like Jupyter, Pycharm, etc.
- Python Basics – Variables, Data Types, Loops, Conditional Statements, functions, decorators, lambda functions, file handling, exception handling ,etc.
- Object Oriented Programming – Introduction to OOPs concepts like classes, objects, inheritance, abstraction, polymorphism, encapsulation, etc.
- Hands-on Sessions And Assignments for Practice – The culmination of all the above concepts with real-world problem statements for better understanding.
Linux
- Introduction to Linux – Establishing the fundamental knowledge of how Linux works and how you can begin with Linux OS.
- Linux Basics – File Handling, data extraction, etc.
- Hands-on Sessions And Assignments for Practice – Strategically curated problem statements for you to start with Linux.
SQL Basics –
- Fundamentals of Structured Query Language
- SQL Tables, Joins, Variables
Advanced SQL –
- SQL Functions, Subqueries, Rules, Views
- Nested Queries, string functions, pattern matching
- Mathematical functions, Date-time functions, etc.
Deep Dive into User Defined Functions
- Types of UDFs, Inline table value, multi-statement table.
- Stored procedures, rank function, SQL ROLLUP, etc.
SQL Optimization and Performance
- Record grouping, searching, sorting, etc.
- Clustered indexes, common table expressions.
Hands-on exercise:
Writing comparison data between the past year and the present year with respect to top products, ignoring the redundant/junk data, identifying the meaningful data, and identifying the demand in the future(using complex subqueries, functions, pattern matching concepts).
Extract Transform Load
- Web Scraping, Interacting with APIs
Data Handling with NumPy
- NumPy Arrays, CRUD Operations, etc.
- Linear Algebra – Matrix multiplication, CRUD operations, Inverse, Transpose, Rank, Determinant of a matrix, Scalars, Vectors, Matrices.
Data Manipulation Using Pandas
- Loading the data, data frames, series, CRUD operations, splitting the data, etc.
Data Preprocessing
- Exploratory Data Analysis, Feature engineering, Feature scaling, Normalization, standardization, etc.
- Null Value Imputations, Outliers Analysis and Handling, VIF, Bias-variance trade-off, cross-validation techniques, train-test split, etc.
Data Visualization
- Bar charts, scatter plots, count plots, line plots, pie charts, donut charts, etc. with Python matplotlib.
- Regression plots, categorical plots, area plots, etc, with Python seaborn.
Descriptive Statistics –
- Measure of central tendency, the measure of spread, five points summary, etc.
Probability
- Probability Distributions, Bayes’ theorem, central limit theorem.
Inferential Statistics –
- Correlation, covariance, confidence intervals, hypothesis testing, F-test, Z-test, t-test, ANOVA, chi-square test, etc.
Introduction to Machine Learning
- Supervised, Unsupervised Learning.
- Introduction to scikit-learn, Keras, etc.
Regression
- Introduction classification problems, Identification of a regression problem, dependent and independent variables.
- How to train the model in a regression problem.
- How to evaluate the model for a regression problem.
- How to optimize the efficiency of the regression model.
Classification
- Introduction to classification problems, Identification of a classification problem, and dependent and independent variables.
- How to train the model in a classification problem.
- How to evaluate the model for a classification problem.
- How to optimize the efficiency of the classification model.
Clustering
- Introduction to clustering problems, Identification of a clustering problem, dependent and independent variables.
- How to train the model in a clustering problem.
- How to evaluate the model for a clustering problem.
- How to optimize the efficiency of the clustering model.
Supervised Learning
- Linear Regression – Creating linear regression models for linear data using statistical tests, data preprocessing, standardization, normalization, etc.
- Logistic Regression – Creating logistic regression models for classification problems – such as if a person is diabetic or not, if there will be rain or not, etc.
- Decision Tree – Creating decision tree models on classification problems in a tree like format with optimal solutions.
- Random Forest – Creating random forest models for classification problems in a supervised learning approach.
- Support Vector Machine – SVM or support vector machines for regression and classification problems.
- Gradient Descent – Gradient descent algorithm that is an iterative optimization approach to finding the local minimum and maximum of a given function.
- K-Nearest Neighbors – A simple algorithm that can be used for classification problems.
- Time Series Forecasting – Making use of time series data, gathering insights and useful forecasting solutions using time series forecasting.
Unsupervised Learning
- K-means – The k-means algorithm that can be used for clustering problems in an unsupervised learning approach.
- Dimensionality reduction – Handling multi dimensional data and standardizing the features for easier computation.
- Linear Discriminant Analysis – LDA or linear discriminant analysis to reduce or optimize the dimensions in the multidimensional data.
- Principal Component Analysis – PCA follows the same approach in handling the multidimensional data.
- Classification reports – To evaluate the model on various metrics like recall, precision, f-support, etc.
- Confusion matrix – To evaluate the true positive/negative, and false positive/negative outcomes in the model.
- r2, adjusted r2, mean squared error, etc.
Artificial Intelligence Basics
- Introduction to keras API and TensorFlow
Neural Networks
- Neural networks
- Multi-layered Neural Networks
- Artificial Neural Networks
Deep Learning
- Introduction to Deep Learning (by Academic Faculty)
- Deep neural networks
- Convolutional Neural Networks
- Recurrent Neural Networks
- GPU in deep learning
- Autoencoders, restricted boltzmann machine
The Data Science capstone project focuses on establishing a strong hold of analyzing a problem and coming up with solutions based on insights from the data analysis perspective. The capstone project will help you master the following verticals:
- Extracting, loading and transforming data into usable format to gather insights.
- Data manipulation and handling to pre-process the data.
- Feature engineering and scaling the data for various problem statements.
- Model selection and model building on various classification, regression problems using supervised/unsupervised machine learning algorithms.
- Assessment and monitoring of the model created using the machine learning models.
- Recommendation Engine – The case study will guide you through various processes and techniques in machine learning to build a recommendation engine that can be used for movie recommendations, restaurant recommendations, book recommendations, etc.
- Rating Predictions – This text classification and sentiment analysis case study will guide you towards working with text data and building efficient machine learning models that can predict ratings, sentiments, etc.
- Census – Using predictive modeling techniques on the census data, you will be able to create actionable insights for a given population and create machine learning models that will predict or classify various features like total population, user income, etc.
- Housing – This real estate case study will guide you towards real world problems, where a culmination of multiple features will guide you towards creating a predictive model to predict housing prices.
- Object Detection – A much more advanced yet simple case study that will guide you toward making a machine learning model that can detect objects in real-time.
- Stock Market Analysis – Using historical stock market data, you will learn about how feature engineering and feature selection can provide you with some really helpful and actionable insights for specific stocks.
- Banking Problem – A classification problem that predicts consumer behavior based on various features using machine learning models.
- AI Chatbot – Using the NLTK python library, you will be able to apply machine learning algorithms and create an AI chatbot.
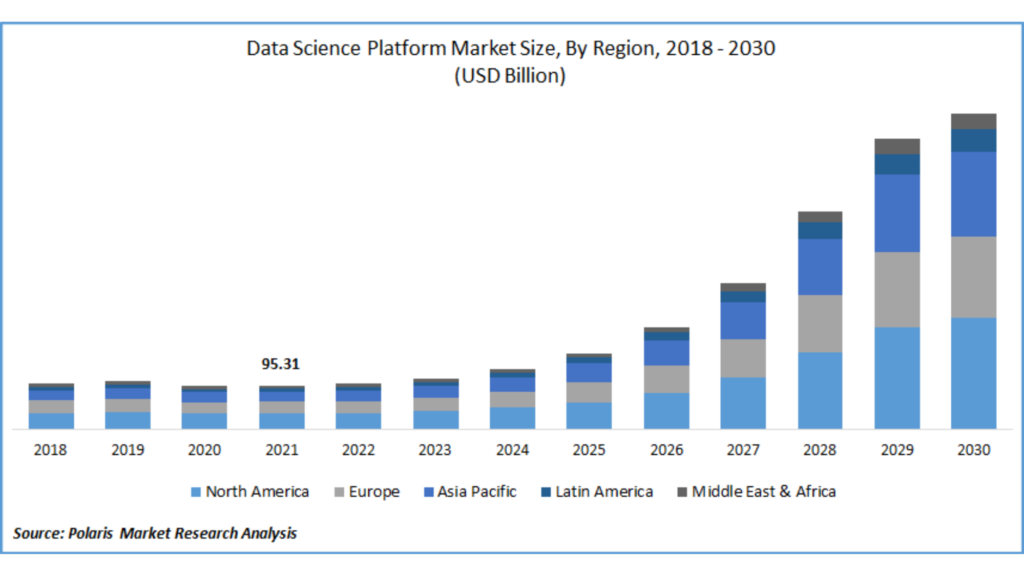
Data Science course is suitable for individuals seeking to harness the power of data for insights and decision-making. It's ideal for aspiring data scientists, analysts, business professionals, and anyone interested in extracting knowledge from data. A strong foundation in math and programming can be beneficial, but it accommodates various skill levels.
Prerequisites for learning Data Science typically include a strong foundation in mathematics and statistics, proficiency in a programming language like Python or R, and basic knowledge of data manipulation and visualization. Additionally, familiarity with databases and domain-specific expertise in fields like business, healthcare, or finance can be advantageous for effective data analysis and interpretation.
Enrolling in a Data Science online course in India offers several advantages. It equips individuals with in-demand skills for the data-driven job market, enhancing career prospects. Online courses provide flexibility, allowing learners to balance study with work commitments. Moreover, Data Science certifications validate expertise and open doors to diverse industries seeking data professionals.